

GAN의 가장 기본적인 논문이라고 할 수 있는 DCGAN을 간단히 리뷰하고 코드 구현까지 담아보려고 한다.
Ian Goodfellow가 GAN을 발표한 이후로 많은 분야의 GAN 연구가 진행되었지만 그 때마다 항상 불안정한 구조로 인한 문제가 따라붙었다. 따라서 큰 이슈였던 부분이 바로 "GAN의 안정화"였다.
Minimax 혹은 saddle problem을 풀어야하는 GAN은 어쩔 수 없이 태생적으로 불안정할 수 밖에 없었다. 이론적으로는 fixed solution으로 수렴하는 것이 보장되어 있지만, 실제 적용에서는 이론적 가정이 깨지면서 생기는 불안정한 구조적 단점을 보이곤 했다. 또한 MNIST와 같이 비교적 단순한 이미지는 괜찮은 이미지를 생성하였지만, CIFAR-10과 같은 복잡한 영상에 대해서는 그렇게 좋은 이미지를 생성했다고 볼 수 없다.
DCGAN 논문의 저자들은 이 문제를 해결하기 위해, CNN을 적용하기 위해 다양한 구조에 대한 실험 끝에 최적이라고 생각되는 구조를 찾아냈으며, DCGAN 이후에 발표된 다른 대부분의 논문들에서는 이들이 발견한 구조를 사용하고 있다.
또한 이들은 입력 데이터로 사용하는 입력 잡음(input noise) z에 대한 의미를 발견하였다. Generator의 입력으로 들어가는 z 값을 살짝 바꾸면, 생성되는 이미지가 그것에 감응하여 살짝 변하게 되는 vector arithmetic의 개념을 찾아냈다.
DCGAN은 이름에서 알 수 있듯이 Convolutional 구조를 GAN에 녹인 것이다.
DCGAN의 구조적 특징

Generator

* Fractionally-strided convolution이란? (= Transposed convolution)
(※ 몇몇 논문에서는 이를 deconvolution이라고 표기하는데 이는 잘못된 표현이다.)
fractionally strided convolution이란 stride의 크기가 1보다 작은 경우로 convolution을 수행하기 때문에 결과적으로 보면 원영상의 중간에 0을 끼워 넣고 convolution을 수행하여 영상의 크기를 크게 만드는 효과를 얻을 수 있으며, 결과적으로 보면 up-sampling이 가능하게 된다.

Discriminator

Vector arithmetic
KING (왕) − MAN (남자) + WOMAN (여자) = ?
정답은 QUEEN (여왕)이 될 것이다. 이와 같은 연산을 이미지에서 했다는 게 DCGAN의 또 다른 큰 특징이다.


결과를 보면 알 수 있듯이 학습을 통해서 얻어진 z 값들을 이용한 vector arithmetic이 가능하다. 학습을 제대로 수행을 하게 되면, latent variable z값이 의미 없는 값이 아니라 각각의 영상이 갖고 있는 representation을 제대로 나타낸다.
PyTorch Code
<details>
- Batch size : 128
- Weights는 standard deviation 0.02를 갖는 zero centered Normal distribution으로 초기화 됨
- LeakyReLU : 0.2
- Batch_norm은 G의 output layer와 D의 input layer를 제외한 모든 layer에 적용함 (이 부분 주의해서 구현하기)
- Discriminator는 마지막 output channel 크기가 512인 것 같음 (G와 완전 대칭구조는 아님)

- Adam optimizer
- Learning rate : 0.001 (너무 크면 0.0002, 코드구현은 0.0002로 함)
- Momentum term β1 : 0.5로 줄이면 훈련 안정화에 도움이 된다고 함
model.py
"""
Discriminator and Generator implementation from DCGAN paper
"""
import torch
import torch.nn as nn
class Discriminator(nn.Module):
def __init__(self, channels_img, features_d):
super(Discriminator, self).__init__()
self.disc = nn.Sequential(
# Input : N(batch_size) x C x H(64) x W(64)
nn.Conv2d( # batch_norm : X
channels_img, features_d, kernel_size=4, stride=2, padding=1
), # 32x32 = (64-4+2/2)+1
nn.LeakyReLU(0.2),
self._block(features_d, features_d*2, 4, 2, 1), # 16x16
self._block(features_d*2, features_d*4, 4, 2, 1), # 8x8
self._block(features_d*4, features_d*8, 4, 2, 1), # 4x4
nn.Conv2d(features_d*8, 1, kernel_size=4, stride=2, padding=0), # 1x1 # batch_norm : X
nn.Sigmoid(),
)
def _block(self, in_channels, out_channels, kernel_size, stride, padding):
return nn.Sequential(
nn.Conv2d(
in_channels,
out_channels,
kernel_size,
stride,
padding,
bias=False,
),
nn.BatchNorm2d(out_channels),
nn.LeakyReLU(0.2),
)
def forward(self, x):
return self.disc(x)
class Generator(nn.Module):
def __init__(self, z_dim, channels_img, features_g):
super(Generator, self).__init__()
self.gen = nn.Sequential(
# Input: N x z_dim x 1 x 1
self._block(z_dim, features_g*16, 4, 1, 0), # N x f_g*16 x 4 x 4 # features_g = 64
self._block(features_g*16, features_g*8, 4, 2, 1), # 8x8
self._block(features_g*8, features_g*4, 4, 2, 1), # 16x16
self._block(features_g*4, features_g*2, 4, 2, 1), # 32x32
nn.ConvTranspose2d( # batch_norm : X
features_g*2, channels_img, kernel_size=4, stride=2, padding=1,
),
nn.Tanh(), # normalize image to [-1, 1]
)
def _block(self, in_channels, out_channels, kernel_size, stride, padding):
return nn.Sequential(
nn.ConvTranspose2d(
in_channels,
out_channels,
kernel_size,
stride,
padding,
bias=False,
),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
)
def forward(self, x):
return self.gen(x)
def initialize_weights(model):
# Initializes weights according to the DCGAN paper
for m in model.modules():
if isinstance(m, (nn.Conv2d, nn.ConvTranspose2d, nn.BatchNorm2d)):
nn.init.normal_(m.weight.data, 0.0, 0.02)
def test():
N, in_channels, H, W = 8, 3, 64, 64
noise_dim = 100
x = torch.randn((N, in_channels, H, W))
disc = Discriminator(in_channels, 8)
assert disc(x).shape == (N, 1, 1, 1), "Discriminator test failed" # assert는 뒤의 조건이 True가 아니면 AssertError를 발생한다.
gen = Generator(noise_dim, in_channels, 8)
z = torch.randn((N, noise_dim, 1, 1))
assert gen(z).shape == (N, in_channels, H, W), "Generator test failed"
# test()train.py
"""
Training of DCGAN network on MNIST dataset with Discriminator
and Generator imported from models.py
"""
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.datasets as datasets
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from model import Discriminator, Generator, initialize_weights
# Hyperparameters etc.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
LEARNING_RATE = 2e-4
BATCH_SIZE = 128
IMAGE_SIZE = 64
CHANNELS_IMG = 1 # MNIST = 1
Z_DIM = 100
NUM_EPOCHS = 5
FEATURES_DISC = 64
FEATURES_GEN = 64
transforms = transforms.Compose(
[
transforms.Resize(IMAGE_SIZE),
transforms.ToTensor(), # 인풋값을 네트워크에 올리기위해 텐서로 변환하는 함수
transforms.Normalize(
[0.5 for _ in range(CHANNELS_IMG)], [0.5 for _ in range(CHANNELS_IMG)]), # CHANNELS_IMG가 달라지더라도 수정할 필요 없게끔
]
)
# data 불러오기
dataset = datasets.MNIST(root="dataset/", train=True, transform=transforms,download=True) #MNIST
#dataset = datasets.ImageFolder(root="C:/Users/zz/.vscode/DCGAN/celeb_dataset", transform=transforms) # celebA
dataloader = DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True)
# 네트워크 선언
gen = Generator(Z_DIM, CHANNELS_IMG, FEATURES_GEN).to(device)
disc = Discriminator(CHANNELS_IMG, FEATURES_DISC).to(device)
# 네트워크 가중치를 초기화함
initialize_weights(gen)
initialize_weights(disc)
# Optimizer 선언
opt_gen = optim.Adam(gen.parameters(), lr=LEARNING_RATE, betas=(0.5, 0.999)) # 논문에 맞게 Adam beta term을 조정해줌 : 0.5 -> 학습 안정화
opt_disc = optim.Adam(disc.parameters(), lr=LEARNING_RATE, betas=(0.5, 0.999))
# Initialize BCELoss function
criterion = nn.BCELoss()
fixed_noise = torch.randn(32, Z_DIM, 1, 1).to(device)
writer_real = SummaryWriter(f"logs/real")
writer_fake = SummaryWriter(f"logs/fake")
step = 0
gen.train()
disc.train()
for epoch in range(NUM_EPOCHS):
# Target labels not needed! <3 unsupervised
for batch_idx, (real, _) in enumerate(dataloader):
real = real.to(device) # real data -> D의 real input
noise = torch.randn(BATCH_SIZE, Z_DIM, 1, 1).to(device) # G input은 랜덤 샘플된 100차원 벡터, batch_size, 100(channel), 1(H), 1(W)
fake = gen(noise) # fake data
### Train Discriminator: max log(D(x)) + log(1 - D(G(z)))
disc_real = disc(real).reshape(-1) # real data를 D에 넣음. 이 결과가 True(1)를 갖게 D 학습.
loss_disc_real = criterion(disc_real, torch.ones_like(disc_real)) # real data를 True(1)을 타겟으로 주고 loss를 구함
disc_fake = disc(fake.detach()).reshape(-1) # G로 생성한 fake data를 D에 넣음 / detach()는 G까지 gradient가 흘러가지 않도록 분리시켜주는 것. # 이 결과가 False(0) 갖게 D 학습.
loss_disc_fake = criterion(disc_fake, torch.zeros_like(disc_fake)) # fake data는 False(0)을 타겟으로 주고 loss를 구함
loss_disc = (loss_disc_real + loss_disc_fake) / 2 # total D loss
disc.zero_grad() # backward를 하기 전에 변화도를 0으로 초기화
loss_disc.backward() # gradient backprop
opt_disc.step() # gradient update
### Train Generator: min log(1 - D(G(z))) <-> max log(D(G(z))
output = disc(fake).reshape(-1)
loss_gen = criterion(output, torch.ones_like(output)) # G는 생성한 fake data를 True(1)로 분류되게 학습함.
gen.zero_grad() # backward를 하기 전에 변화도를 0으로 초기화
loss_gen.backward() # gradient backprop
opt_gen.step() # gradient update
# 일정한 간격으로 Print loss & print to tensorboard
if batch_idx % 100 == 0:
print(
f"Epoch [{epoch}/{NUM_EPOCHS}] Batch {batch_idx}/{len(dataloader)} \
Loss D: {loss_disc:.4f}, loss G: {loss_gen:.4f}"
)
with torch.no_grad():
fake = gen(fixed_noise)
# 32개의 예를 든다.
img_grid_real = torchvision.utils.make_grid(
real[:32], normalize=True
)
img_grid_fake = torchvision.utils.make_grid(
fake[:32], normalize=True
)
writer_real.add_image("Real", img_grid_real, global_step=step)
writer_fake.add_image("Fake", img_grid_fake, global_step=step)
step += 1
MNIST 이미지 학습과정
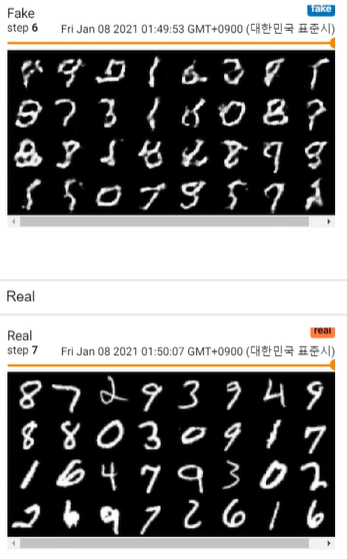
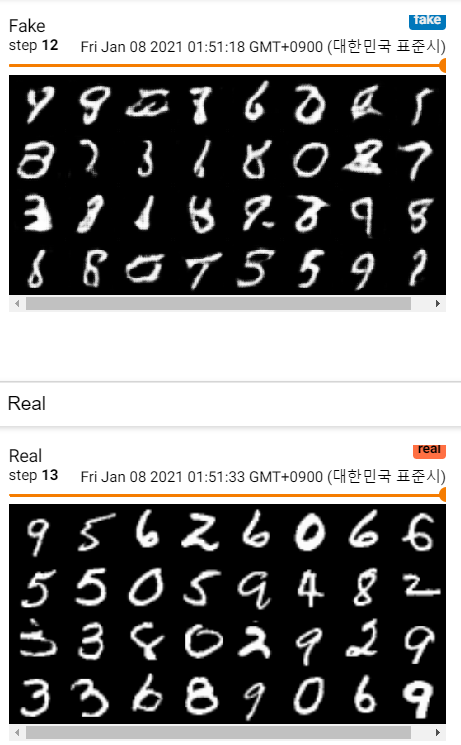
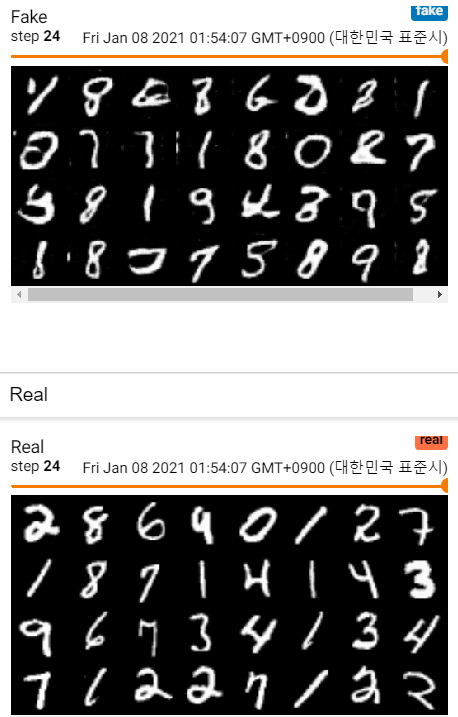
참고 자료 :
(2) PyTorch DCGAN Tutorial - Improving the architecture with CNNs - YouTube
jaejunyoo.blogspot.com/2017/02/deep-convolutional-gan-dcgan-1.html
[Part VIII. GAN] 2. DCGAN - 라온피플 머신러닝 아카데미 : 네이버 블로그 (naver.com)
'Computer Vision > GAN' 카테고리의 다른 글
| [ECCV 2020] GAN Slimming 논문 리뷰 (0) | 2021.01.05 |
|---|---|
| [ICLR 2020] On the 'steerability' of generative adversarial networks 논문 리뷰 (0) | 2021.01.04 |
| GAN 종류 정리 (0) | 2021.01.03 |
| GAN(Generative Adversarial Networks) 개념 정리 - 2 (0) | 2021.01.03 |
| GAN(Generative Adversarial Networks) 개념 정리 - 1 (0) | 2021.01.03 |
