논문 : arxiv.org/abs/1406.2661 [NIPS 2014]
1. GAN이란?
GAN(Generative Adversarial Networks)이란 말 그대로 '적대적 생성 모델'이라고 할 수 있다. Ian Goodfellow는 논문에서 지폐위조범과 경찰로 예를 들어 설명하고 있다.

이와 같이 GAN은 "이미지를 만들어 내는 생성자(Generator)와 이렇게 만들어진 녀석을 평가하는 판별자(Discriminator)가 서로 대립(Adversarial)하며 서로의 성능을 점차 개선해 나가는 모델"이다.
- Generator : 임의의 설정된 정보(latent space)를 바탕으로 가상의 이미지를 만들어 내는 신경망 구조의 생성 시스템.
- Discriminator : 입력된 이미지가 진짜 이미지일 확률(0과 1 사이 값)을 출력값으로 하여 일치의 정도를 출력하는 시스템.
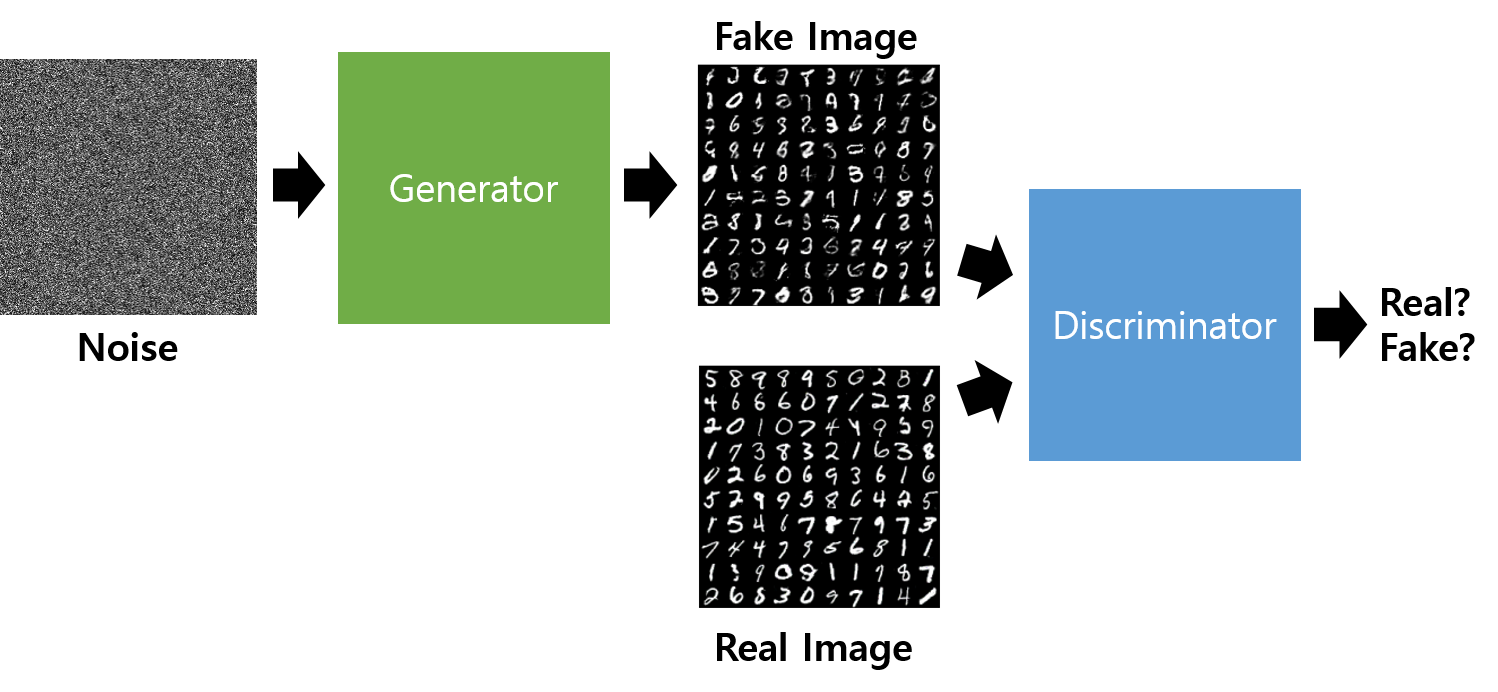
GAN의 구조는 다음과 같다. 먼저 G는 Random Noise를 input으로 받아 Neural Network를 거쳐 Fake Image를 생성한다. 그리고 D는 Fake Image 또는 Real Image를 input으로 받아 NN을 거쳐 0과 1 사이의 값을 출력하게 되는데, 이 값은 D가 나름대로 판단한 'Input이 Real Image일 확률'이다. 즉, 이상적인 D는 Real Image를 받으면 1을, Fake Image를 받으면 0을 출력해야 한다.
*Random Noise / latent sample(잠재 공간에서의 샘플 데이터) : 보통 Gaussian Distribution으로 Noise를 생성한다. latent space를 조작해 gan의 성능을 높이는 연구도 활발하게 진행중이다..
2. GAN의 최적화 과정

GAN이 최적화 되는 과정은 다음과 같다. (a)에서 (d)로 갈수록 원본 이미지 x의 분포와 latent space z의 분포가 비슷해진다. 따라서 점점 더 그럴듯한 이미지를 생성해내게 되는 것이다.
3. GAN의 비용함수

-
x : Real data
-
z : G가 input으로 받는 Noise
-
G(z) : G가 Noise를 받아서 생성해 낸 Fake data
-
D(x) : D가 Real data를 받고 출력하는 값
-
D(G(z)) : D가 Fake data를 받고 출력하는 값
3.1 D는 V(D,G)를 Maximize 한다.

D의 값의 범위가 0~1이므로 logD의 값의 범위는 -∞~0이다. 따라서 V(D,G)식을 최대화 하기위해선 log1+log1 꼴이 되어야 한다. 그러므로 D(x)=1 에 가까운 값을 갖도록 학습되고, D(G(z))=0에 가까운 값을 갖도록 학습되는데 이와 같은 식을 통해 진짜 이미지(x)는 진짜(1)라고 판별하고, 만들어낸 가짜 이미지(G(z))는 가짜(0)라고 판별할 수 있는 것이다.
3.2 G는 V(D,G)를 minimize한다.

G는 V(D,G)를 minimize하도록 학습이 된다. 따라서 D(G(z)) = 1에 가까운 값을 내도록 학습되는데 이와 같은 식을 통해 가짜 이미지(G(z))를 D가 진짜(1)라고 믿게끔 진짜같은 이미지를 생성해내게 되는 것이다.
3.3 수정된 G loss
Minimize log(1-D(G(z))) 는 Maximize log(D(G(z)))로 바꿔서 표현할 수 있다. 두 식 모두 D(G(z))=1의 값에 가까워지도록 학습되기 때문이다. 이렇게 G loss를 수정해주는 이유는 그래프를 통해 쉽게 이해할 수 있다.

G는 처음에 형편없는 이미지를 생성해내기 때문에 초반에는 D가 매우 유리한 상태로 시작한다. 따라서 D(G(z))의 값이 0에 가까운데 이 차이를 극복하지 못하면 D가 G를 영원히 압도하게 되는 현상이 발생할 수 있다.
오른쪽 그래프[y=log(1-x)]와 같은 기존의 G loss에서 x에 0을 대입하면 기울기의 절대값이 생각보다 작다. 반면에 왼쪽 그래프[y=log(x)]와 같이 수정된 G loss에서는 x에 0을 대입하면 기울기가 거의 무한대에 가깝게 된다. 따라서 오른쪽 그래프보다 왼쪽 그래프가 초반의 안좋은 상황을 최대한 빨리 벗어나려고 한다.
그렇기 때문에 최종적으로 D와 G는 다음과 같은 수식으로 나타낸다.

4. GAN 코드설명

참고자료 :
jaejunyoo.blogspot.com/2017/01/generative-adversarial-nets-1.html
'Computer Vision > GAN' 카테고리의 다른 글
| [ECCV 2020] GAN Slimming 논문 리뷰 (0) | 2021.01.05 |
|---|---|
| [ICLR 2020] On the 'steerability' of generative adversarial networks 논문 리뷰 (0) | 2021.01.04 |
| [ICLR 2016] DCGAN 개념 및 PyTorch 코드 구현 (0) | 2021.01.03 |
| GAN 종류 정리 (0) | 2021.01.03 |
| GAN(Generative Adversarial Networks) 개념 정리 - 2 (0) | 2021.01.03 |
