
사이트 : ali-design.github.io/gan_steerability/

GAN 스터디 때 나온 주제 중 latent space를 조작하는 연구 분야가 흥미롭게 느껴져서 리뷰하게 된 논문이다.
제목에서 알 수 있듯이 GAN을 latent space에서 "steering" 즉, 조종하려고 한 논문이다. source image를 edit해서 사용하는 self-supervised 방법을 통해 학습을 진행한다.
1. Introduction
GAN은 학습된 데이터셋 내에서의 변환은 잘 하지만 학습 데이터셋에서 완전 벗어난 이미지는 만들 수 없다는 한계가 존재한다.
예를 들어, 트레이닝 데이터셋에 긴 머리를 가진 남자의 이미지는 없다고 가정하면 "남자 = 머리가 짧다" 라고 데이터에 bias(편향)이 생겨버리기 때문에, 여자를 남자로 바꾸는 변형을 할 때 짧은 머리를 가진 남자 이미지만 생성하고 긴 머리를 가진 남자 이미지는 생성하기 어려워진다.
따라서 본 논문에서는 이러한 변환의 한계를 정량화 하고 문제를 완화하기 위한 실험을 수행했다.
GAN이 생성할 수 있는 이미지의 범위를 확장하기 위해 잠재 공간(latent space)을 조종(steering)하는 방법을 사용했다.
논문에서는 "drive in the latent space"라는 표현을 사용하고 있다. 잠재 공간을 조종함으로써 Fig1에 나온 [Zoom, Brightness, Shift Y, Shift X, Rotate2D, Rotate3D] 이러한 변환(transformation)을 할 수 있게 되는데 이를 통해 GAN이 좀 더 Real World를 담아낼 수 있게끔 한 것이다.
2. Proposed Methods
GAN은 mapping function G : z →x 를 학습하는 생성모델이다. 본 논문에서는 두 가지의 Linear walk/Non-linear walk 가 나오는데 먼저 Linear walk에 대해 설명하겠다.
2.1 Linear walk
위의 그림으로 예를 들면, 잠재 공간의 sample z를 w만큼 linear하게 이동시켜 주면 원래 z에서 생성한 이미지 G(z)보다 조금 Zoom 된 꽃 이미지 G(z+w)가 만들어지게 된다.
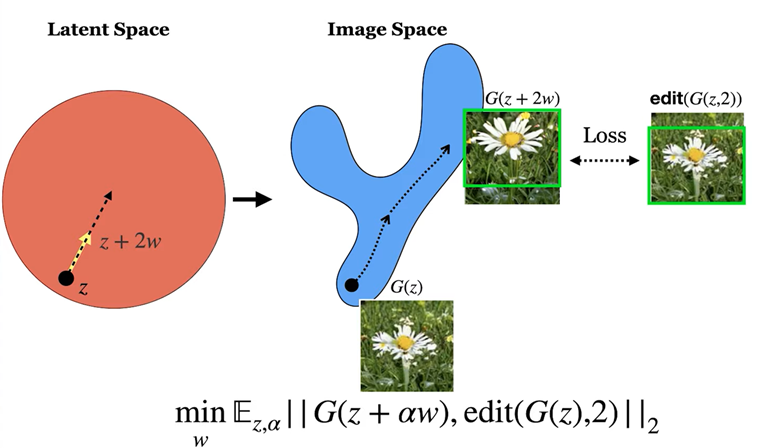
2w만큼 linear하게 이동하면 조금 더 Zoom된 꽃 이미지 G(z+2w)가 나오게 된다.
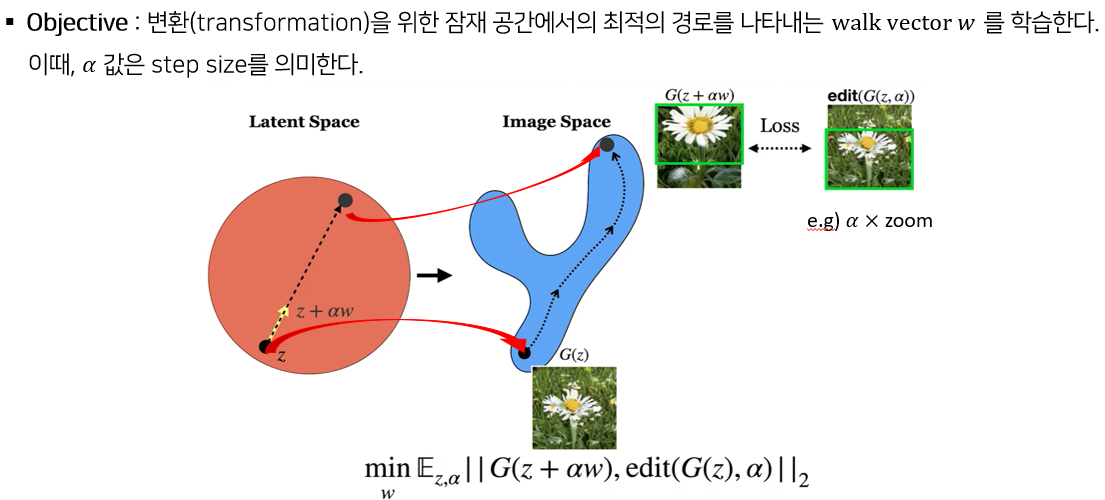
이런 원리를 사용해서 앞서 설명드린 확대/축소, 밝기 변화 등의 변환을 위한 잠재 공간에서의 최적의 경로를 나타내는 walk vector w를 학습하는게 목표이다.
최적의 경로는 위의 식을 통해 구한다. Edit(G(z, α)) 는 생성된 이미지 G(z)를 가지고 edit 연산을 한 것이다. 예를 들어, 이 사진에서는 알파 만큼 zoom 연산을 한 것이다.
이것과, latent space 에서 z를 z+αw 방향으로 변환한 값을 가지고 생성한 이미지 G(z+αw) 가 있을 때, L2 loss 를 사용해서 거리를 최소화하는 w를 값을 구하는 것이다.
2.2 Non-linear walk
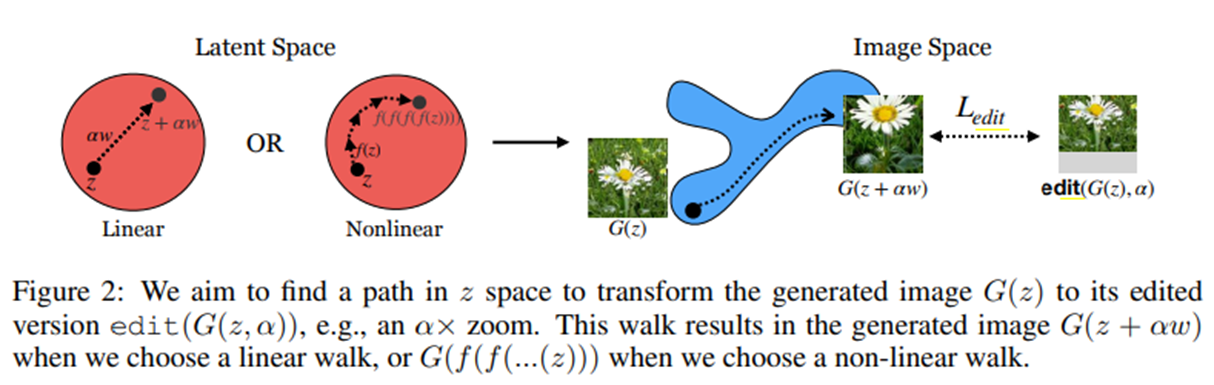
잠재 공간에서의 linear walk 뿐만 아니라 walk의 방향이 바뀌는 non-linear walk의 학습 방법도 제시하고 있다.
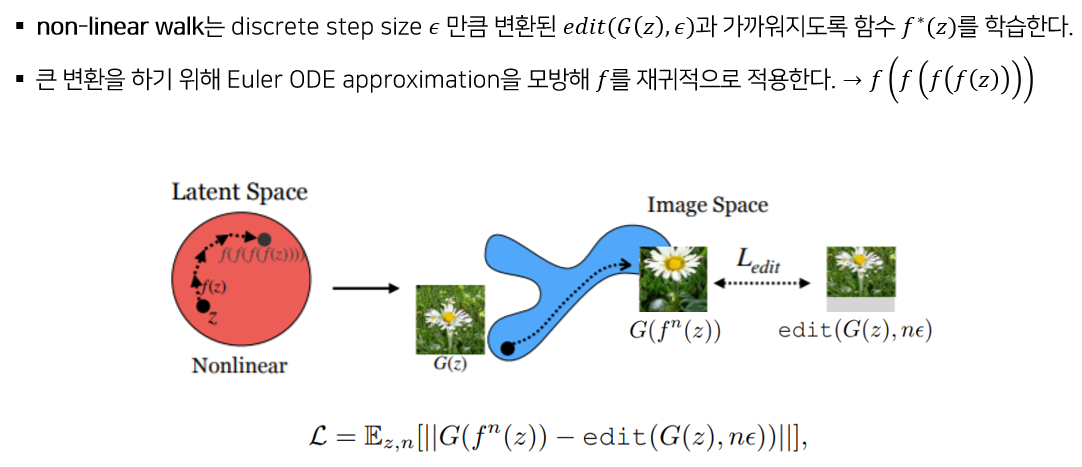
Non-linear walk의 식은 다음과 같다. 큰 변환을 하기 위해 f함수를 재귀적으로 적용했는데 이는 Euler ODE approximation을 모방한 것이라고 한다.
* Euler ODE approximation
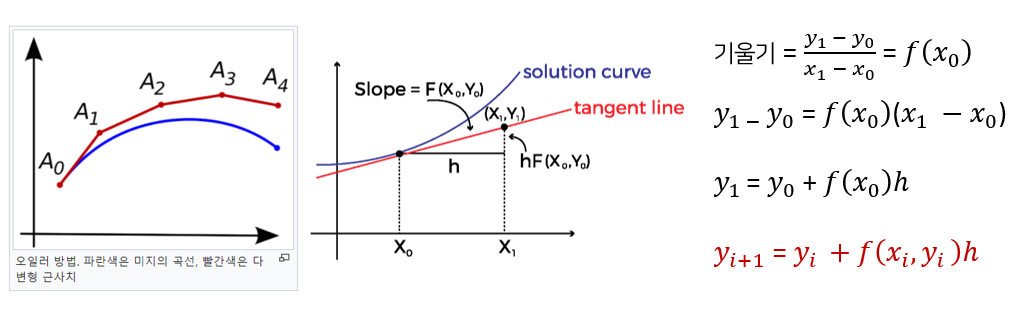
오일러 상미분 방적식은 형태가 알려지지 않은 파란색의 미지의 곡선을 계산하기 위한 방법으로 시작점 A0를 알고 있다면 A0 지점의 접선의 기울기를 구할 수 있고, 이와 같은 방법을 반복해서 빨간색과 같은 근사치를 구하는 것이다.
일반화하면 빨간색 식과 같아지는데 이런 방법을 사용해서 비선형 변환을 추정하는 것이다.
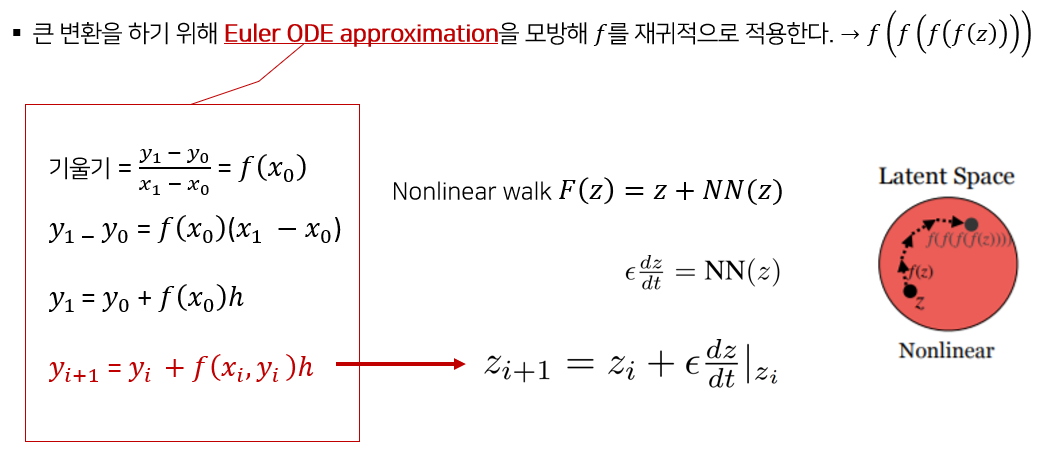
Nonlinear walk F(z) 는 다음과 같이 z+NN(z)로 표현된다. 여기서 NN은 Neural Network 를 의미한다. 신경망 NN은 엡실론(ϵ) step 변환을 학습하므로 다음과 같이 잠재 공간에서의 변환의 기울기로 표현할 수 있다. 따라서 오일러 상미분 방정식을 모방한 다음과 같은 식으로 나타낼 수 있다.
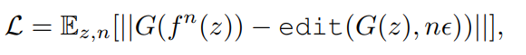
Nonlinear walk 는 이렇게 z를 재귀적으로 n번 합성한 f^n (z)에서 생성한 이미지와 z에서 생성한 이미지 G(z)를 nϵ 만큼 편집한 이미지의 차를 최소화 하도록 학습 된다.
2.3 Reducing transformation limits
앞서 설명한 방법들은 pre-trained model을 가정하기 때문에 generator의 weight은 고정된 채로 Linear-walk / Non-linear walk만 학습시켰는데 실험 결과 변환에 한계가 존재했다고 한다. 따라서 변환 한계를 줄이기 위해 Generator 의 weight 와 walk vector 를 공동으로 최적화하는 방법을 사용했다고 한다.
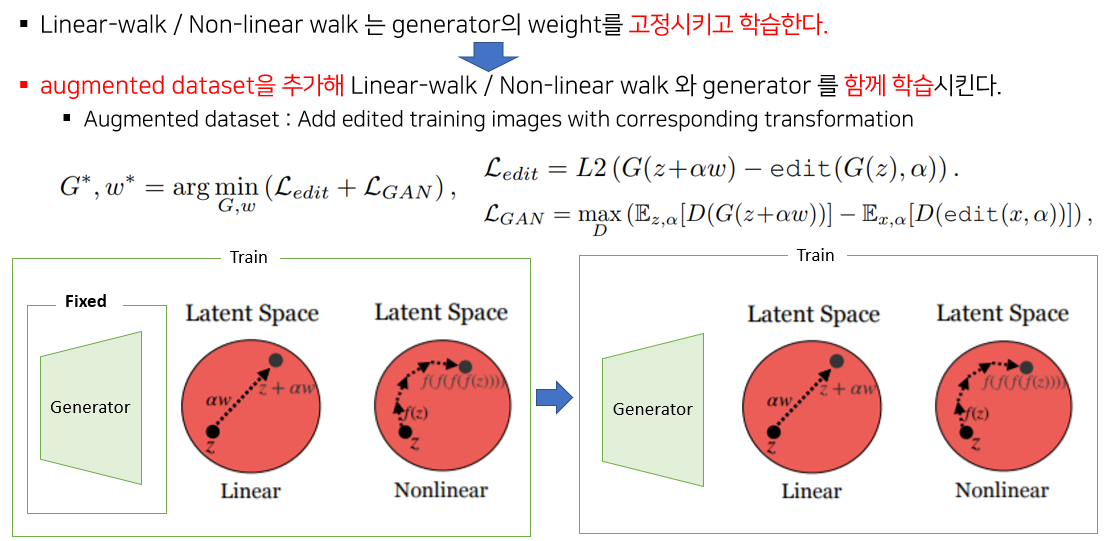
수정된 목적함수는 위와 같다. training dataset에서 image x를 뽑고 edit 하는 방식으로 만든 augmented dataset을 추가하고 기존의 edit loss를 통해 walk vector 들을 학습한다. 여기에 generator 를 학습시키는 GAN loss를 추가해준 것이다.
3. Experiments
- 1000개의 ImageNet categories에서 학습된 BigGAN을 사용해서 실험을 진행했다.
- 이미지 카테고리 전체에 걸쳐 평균을 냄으로써 shared latent space walk 를 배우고 각 클래스에 어떻게 다른 영향을 미치는지 추가적으로 정량화 했다.
- 각 변환(transformation)은 direct supervision 없이 source image를 edit 함으로써 학습된다. → self-supervised 방식
- 변환 종류 : Shift X, Shift Y, Zoom, Color (RGB), Rotate 2D/3D ( -45~ 45)
3.1 Qualitative results of the learned transformations

Generator latent space를 조종(steering)함으로써 다양한 변환을 학습할 수 있는데, 흥미롭게도 이러한 변환을 배울 때, 몇가지 사전 지식이 적용된다고 한다. 예를 들어, 데이지를 Y방향으로 아래쪽으로 이동하면 모델은 상단에 하늘이 존재한다고 만들어내고, 위로 이동하면 나머지에 잔디를 채운다. 또한 이미지의 밝기를 조정하면 야간과 주간같이 바뀝니다.
(이와 같은 현상이 발생하는 것은, 소스 이미지들로 부터 영향을 받고, 조정하더라도 여전히 문맥적인 정보가 남아있음을 보여준다. / 소스 데이터셋과 연관된 이미지를 생성할 수 밖에 없다는 의미)
3.2 Transformation limit

또한 변환에는 한계가 있는 것을 확인할 수 있다. 예를 들어 열기구 이미지를 변환하는 것은 큰 폭으로 되지만,
아래와 같이 이미지넷 사진들에서는 step size α를 늘리고 줄여봤을때 변환에 한계가 있다는 것을 알 수 있다.
고양이를 확대하려고 할 때 특정 지점을 넘어서면 크기가 증가하지 않고, 어느 시점부터는 더 이상 작아지지 않는다.
잉꼬는 어느 정도 위 아래로 이동할 수 있지만 특정 지점을 넘어서면 비현실적으로 변한다.
이는 ImageNet 사진들이 대부분 객체를 중심에 두고 있고, 고양이를 엄청 확대한 사진 같은 것은 없기 때문이다.

또한 빨간색을 조종하면 해파리는 변환이 되지만 노란색 새는 클래스에 노란색 밖에 없기 때문에 빨간색으로 바뀌지가 않고, 파란색을 조종하면 빨간색 스포츠카는 파란색으로 바뀌지만 소방차는 빨간색밖에 없으므로 파란색으로 바뀌지 않는다. 이는 변환이 개별 클래스의 데이터셋 편향(bias)에 의해 제한된다는 것을 나타낸다.

즉, 가능한 변환의 범위는 데이터셋의 가변성과 관련이 있다는 것이다. 검은색이 데이터셋의 분포를 나타내는 것인데, 울새의 경우에는 가변성이 낮기 때문에 변환이 많이 되지 않은 반면, 노트북의 경우엔 데이터셋이 넓게 분포해 있어서 더 큰 변환이 가능하다.
3.3 Linear vs Non-linear walk

다음은 linear / nonlinear walk 의 결과 비교이다. 보시면 Linear walk 는 큰 변환을 하진 못하지만 보다 현실적인 이미지를 생성하고 nonlinear walk는 더 큰폭으로 변환하나 현실성이 떨어지는 이미지를 만든다는 것을 알 수 있다.
3.4 Reducing the effect of transformation limits
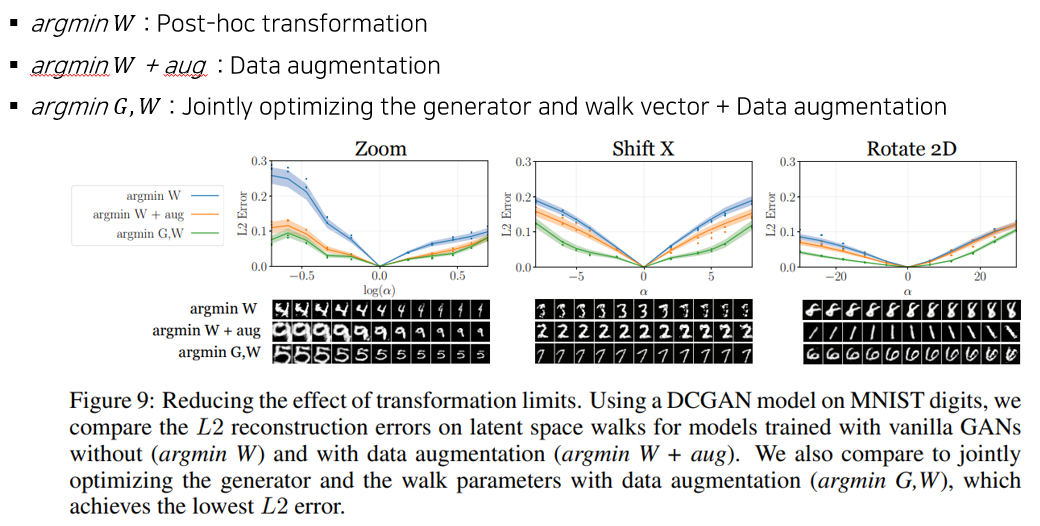
변환 한계를 줄이기 위한 방법을 실험한 것이다. L2 error 를 비교한 그래프인데, 파란색 선이 고정된 generator 를 사용하는 기존 모델이고 주황색 선은 여기에 데이터만 늘려서 추가한 것이다. 보면 더 낮은 L2 error를 보이는 것을 알 수 있다. 초록색 선은 데이터를 늘려서 generator 와 walk vector 를 공동으로 최적화시킨 방법인데 가장 낮은 L2 error 를 보이는 것을 확인할 수 있다.
따라서 데이터 증강과 G와 W의 공동학습은 변화 한계를 줄이는데 도움이 된다는 것을 알 수 있다.
4. Conclusion
- GAN이 학습 데이터 포인트를 단순히 복제하는 것인지 아니면 학습 분포를 넘어 일반화 할 수 있는지에 대한 답을 구하는 논문이다.
- 결론적으로 이미지를 어느정도 변환할 수는 있지만 학습 데이터를 아예 벗어나는 이미지는 생성할 수 없다.
- 따라서 모델이 생성할 수 있는 이미지의 범위를 확장하는 방법을 제안했다. (데이터를 늘리고 generator 와 walk vector 를 공동으로 최적화 하는 방법)
+ 느낀점
논문은 11쪽 정도이지만 부록까지 합치면 31쪽이다. 부록에는 수학적 증명 뿐만아니라 굉장히 많은 실험 결과를 보여주고 있다. 앞서 언급한 BigGAN 뿐만 아니라 StyleGAN 등으로 실험을 진행했다. 많은 노력이 들어가 있는 논문이다.
"우리가 ~~~한 새로운 방법을 제안했다!" 라기 보다 GAN의 일반적인 문제점을 언급하면서 이를 해결할 방법에 대한 실험을 진행했고, 결론적으로 완전히 해결하는 방법은 찾지 못했지만 문제를 완화하는 방법은 찾았다고 서술하는 흐름이 잘 와닿았던 논문이다.
또한 제목을 잘 지은 것 같다. 논문을 보다 보면 긴 제목 때문에 다시 봤을 때 이게 뭐에 관한 논문이었더라... 생각하는 경우가 더러 있는데 "steerability"라는 단어를 강조해 줌으로써 latent space 를 조작하는 논문이라는 것을 바로 떠올리게끔 해주었다.
참고 자료 : www.youtube.com/watch?v=nS0V64sF7Cw&feature=youtu.be
'Computer Vision > GAN' 카테고리의 다른 글
| [ECCV 2020] GAN Slimming 논문 리뷰 (0) | 2021.01.05 |
|---|---|
| [ICLR 2016] DCGAN 개념 및 PyTorch 코드 구현 (0) | 2021.01.03 |
| GAN 종류 정리 (0) | 2021.01.03 |
| GAN(Generative Adversarial Networks) 개념 정리 - 2 (0) | 2021.01.03 |
| GAN(Generative Adversarial Networks) 개념 정리 - 1 (0) | 2021.01.03 |
