1. Rich feature hierarchies for accurate object detection and semantic segmentation (2013)
3. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks (2015)
1. R-CNN Architecture
Region Proposal + Convolutional Neural Network (CNN)
Object Detection에서 sliding window 방식은 비효율적이다. 이를 개선하기 위한 방법으로 입력 영상에서 ‘물체가 있을 법한’ 영역을 빠른 속도로 찾아내는 region proposal 알고리즘이 있다. 다양한 region proposal 알고리즘들이 논문으로 발표되었지만, selective search(처음에는 조각조각 Bbox 쳤다가 그걸 조금씩 merge해 나간다)와 Edge boxes 알고리즘이 보편적으로 좋은 성능과 속도를 보여주고 있다.
Region Proposal을 활용하면, 훨씬 빠른 속도로 Object Detection을 수행할 수 있게 된다.
R-CNN은 Image classification을 수행하는 CNN과 이미지에서 물체가 존재할 영역을 제안해주는 region proposal 알고리즘을 연결하여 높은 성능의 object detection을 수행할 수 있음을 제시해 준 논문이다.

1. 이미지를 입력으로 받는다.
2. 이미지로부터 약 2000개 가량의 region proposal을 추출한다.(selective search 활용)
3. 각 region proposal 영역을 이미지로부터 잘라내고(cropping) 동일한 크기로 만든 후(warping), CNN을 활용해 feature를 추출한다.
4. 각 region proposal feature에 대한 classification을 수행한다.

즉, 이미지에서 RoI(Region of Interest Pooling) 를 뽑아내고 각각 CNN에 돌리는데 2000개 가량을 뽑기 때문에
느리다는 단점이 있다. CNN은 input size가 고정되어 있기 때문에 어떤 사이즈의 RoI가 들어오더라도 input size에 맞게끔 Warpping(비뚤려진?)한 이미지를 CNN에 넣어준다.
그리고 일반적인 classification 방법을 쓰지 않고, CNN의 마지막 feature map을 이용해 그것을 SVM을 이용해서classification 하고 있다. 또한 RoI가 정확하진 않기 때문에 미세 조정을 해주기 위해 Bbox regression 네트워크도 추가해줬다.
R-CNN Training
- ConvNet은 AlexNet을 사용했다. AlexNet은 ImageNet classification dataset으로 Pre-train 시켰다.
- 마지막에 classification 할 때, ImageNet은 카테고리가 1000개니까 이것은 잘라내고 detection을 위한 class 수만큼 (20개 정도?) 으로 바꾼다. 그리고 object detection 용 dataset을 cnn에 집어넣고 이걸 가지고 다시 fine-tunning 시킨다.
- ?? 마지막에 있는 feature들을 디스크에 저장하고 그걸 다시 다른곳에서 읽어와서 SVM 학습을 시킴. (hinge loss)
- bounding-box regression(성능을 끌어올리기 위해서 이 박스 위치를 교정해주는 것)도 여기서 학습시킨다.

R-CNN의 단점은 느리다는 것 외에도 SVM이나 bounding-box regression을 학습할 때 학습한 결과가 CNN까지 back-propagation이 안돼서 cnn은 학습이 안된다는 게 있다.
Bounding-Box Regression

P는 처음에 뽑아낸 RoI 좌표이다. center의 x,y 좌표와 Bbox의 width, height 정보를 갖고 있음.
G는 ground truth이다. G와 최대한 가깝게 만드는 d들을 찾아내는게 목표이다.
Problems of R-CNN
- 느리다.
- SVM 이나 bounding box regression 한 결과가 cnn을 업데이트 시키지 못한다는 문제가 있다.
- 복잡한 multistage training pipeline을 가지고 있다.
2. Fast R-CNN
- '속도'를 대폭 개선했다. R-CNN은 각각의 region 마다 이미지를 cropping 한 뒤 CNN 연산을 수행하여 2,000번의 CNN 연산을 진행하게 되는데 이러한 비효율성을 개선하기 위해, cropping 하는 과정을 image level이 아닌 feature map level에서 수행하면 2,000번의 CNN 연산이 1번의 CNN 연산으로 줄어듦으로 연산량 측면에서 훨씬 이득을 볼 수 있다.

- R-CNN, SPP-net이 업데이트가 안되는 문제를 해결했다.
- single stage, end-to-end
Fast R-CNN Architecture

처음 RoI를 뽑아내는건 마찬가지로 Selective Search를 쓴다. R-CNN은 뽑아낸 이미지를 warping을 해서 잘라냈는데 Fast R-CNN은 RoI를 이미지에서 뽑은 다음에 CNN에 그냥 이미지 전체를 한번 집어넣고, 맨 마지막 까지 가면 빨간 박스에 해당되는 영역이 나온다. (RoI projection) 그다음에 매 Bbox마다 RoI pooling(Region of Interest Pooling)을 해서 사이즈를 같게 만들어 준다. 그리고 나서 FC layer를 거쳐서 병렬적으로 처리하는데 하나는 softmax를 거쳐서 RoI 안에 있는 물체에 대한 classification을 한다. 다른 하나는 bbox에 대한 regression 을 한다.

RoI Pooling (Region of Interest Pooling)
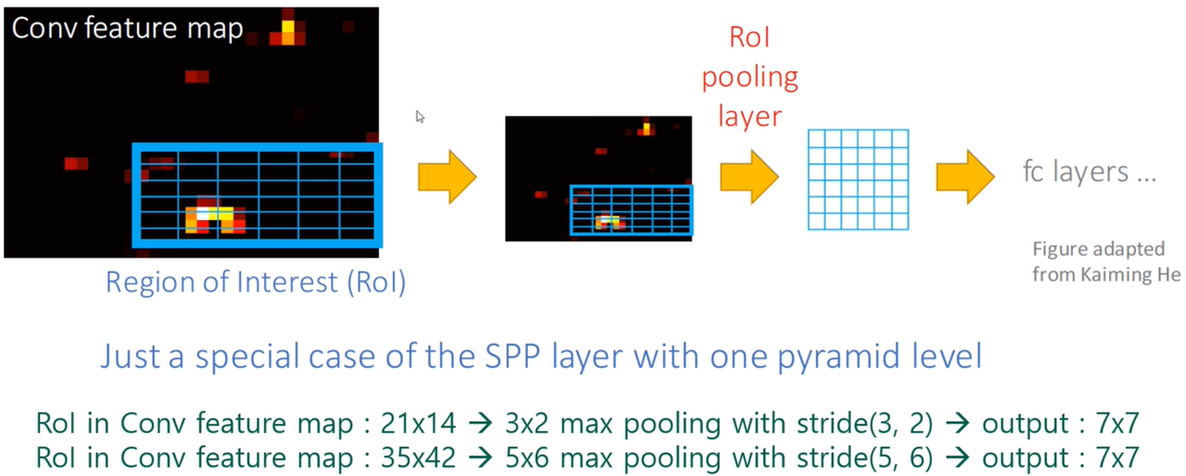
FC layer로 들어가기 위해 똑같은 사이즈의 output이 나오도록 max pooling하는 방법이다.
예를 들어, 항상 max pooling을 해서 결과가 7X7이 되게 만드는 것이다. (21-3/3)+1 = 7 , (14-2/2)+1 = 7
기존의 R-CNN이 selective search * CNN 의 연산량을 수행했다면 Fast R-CNN은 (selective search + RoI Pooling) * 1 의 연산량이 되는 것이다. 이로 인해, 연산량은 급격하게 줄어들게 된다.
Training & Testing
1. input에서 bounding box들을 받음
2. 그것을 convolution feature maps을 이용해 generate하고
3. 각각의 bbox에 대해 RoI pooling layer를 이용해서 고정된 사이즈의 feature vector를 뽑아낸다.
4. 개네들을 FC layer에 넣고 classification(배경까지 K+1개의 class에 대해 학습시킨다.) 과 bbox regression을 양쪽에서 동시에 진행한다.
Problems of Fast R-CNN
- region proposal network 가 밖에 있고 selective search를 이용하는데 그게 test time에 bottleneck을 일으킨다.
- 기존 R-CNN보단 빨라졌지만 2.3초가 정말 빠른가?
3. Faster R-CNN (RPN + Fast R-CNN)
Region Proposal을 Selective Search를 쓰지 말고 실제 네트워크 안에서 같이해보자!
(Selective Search는 CPU에서 돌아서 더 오래걸렸음)
RPN (Region Proposal Network)이란 것을 만들어서 gpu에서 빠르게 해보자.
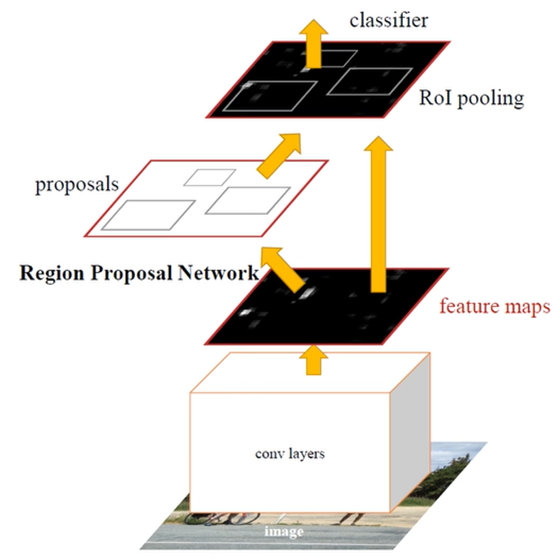
RPN

최상위에 있는 convolutional feature map에서 Conv filter를 더 써서 N X N 크기의 작은 window 영역을 입력으로 받고,
해당 영역에 물체가 존재하는지/존재하지 않는지에 대한 binary classification을 수행하는 작은 classification network를 만들어 볼 수 있다. R-CNN, Fast R-CNN에서 사용되었던 bounding-box regression 또한 위치를 보정해주기 위해 추가로 사용된다. regression 하기 위해 initial한 bbox가 있긴 있어야 해서 나온 개념이 Anchor이다.

Anchor란 3X3 filter가 지나갈 때, 가운데 점을 중심으로 하는 bbox 종류들을 미리 정의해놓은 것이다. 이 논문에서는 9개를 사용한다. 이 각각의 anchor에 대해 object가 있는지 없는지 classification하는 것이다.
<Conv filter가 얼만큼 필요한지 : 예시>
- 처음에는 3X3X256(or 512)개의 filter를 쓴다. stride1, padding 1
- Cls layer : 1X1X18(k가 9고 class가 2개니까) filter, stride1, padding 0
- Reg layer : 1X1X36(k가 9고 각각의 좌표가 4개여서) filter, stride1, padding 0
Anchors는 pre-defined reference boxes이다. 3가지의 scale, 3가지 aspect ration을 써서 총 9개의 anchor를 사용했다.
4-Step Alternating Training

1. 처음에 RPN을 ImageNet으로 pre-trained된 network를 가져와서 학습시킨다. M0 -> M1
2. 학습된 M1 네트워크를 이용해서 RoI를 initial로 뽑는다. 그걸 P1이라고 하면
3. P1과 M0를 fast R-CNN으로 학습시킨다. (오른쪽 긴 화살표) 그럼 M2가 나옴
4. M2를 가져와서 RPN 를 다시 학습시키면 M3가 됨. (아래쪽 Conv layer는 fix시키고 RPN으로 가는 Conv filter들만 학습을 시킴)
5. M3에서 새로운 Region proposal을 뽑음 P2
6. P2와 M3를 가지고 다시 마지막으로 fast R-CNN 을 학습시켜서 M4를 만든다.
7. 최종결과 M4가 나오게 된다.
Results
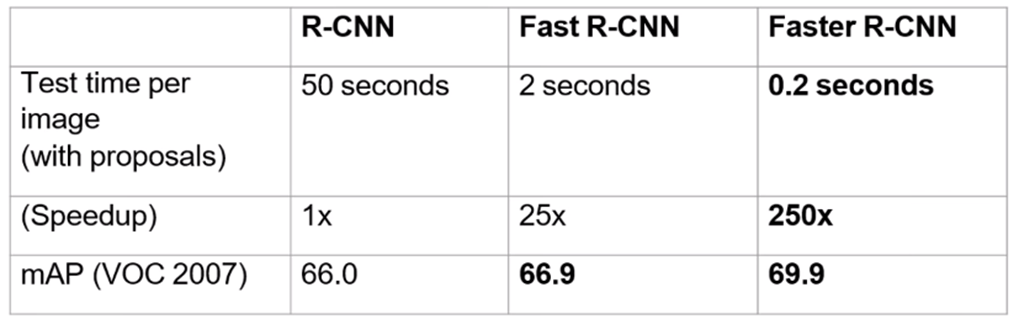
4. Mask R-CNN
Instance Segmentation을 위해 나온 논문. Instance Segmentation을 하기 위해서는 Object detection과 semantic segmentation을 동시에 해야 한다. 이를 위해 Mask R-CNN은 기존의 Faster R-CNN을 Object detection 역할을 하도록 하고 각각의 RoI (Region of Interest)에 mask segmentation을 해주는 작은 FCN (Fully Convolutional Network)를 추가했다.
1. Faster R-CNN에 존재하는 "bbox 인식을 위한 브랜치"에 병렬로 "오브젝트 마스크 예측 브랜치" 추가
2. ROI Pooling 대신 ROI Align 을 사용함
3. Mask prediction 과 class prediction 을 decouple 함 (클래스 상관없이 masking)
기존의 Faster R-CNN은 object detection을 위한 모델이었기 때문에 RoI Pooling 과정에서 정확한 위치 정보를 담는 것은 중요하지 않았다.



RoI Pooling의 경우 위 그림과 같은 과정을 거치는데, 소수점을 반올림한 좌표를 가지고 Pooling을 해주면 input image의 원본 위치 정보가 왜곡된다. 왜곡되면 classificaion task에서는 문제가 발생하지 않지만, 정확하게 pixel-by-pixel 로 detection 하는 segmentation task 에서는 문제가 발생한다.
이를 해결하기 위해 Mask R-CNN 에서는 RoI Pooling 대신에 RoI Align 을 사용했다.

파란색 점선 그리드는 feature map을 나타낸다. 검은색 라인은 RoI(위 그림에선 with 2x2 bins)를 나타낸다.
점은 각 bin에서 4개의 샘플링 포인트를 나타낸다.
RoI Align은 피쳐맵 위에 있는 그리드 포인트로부터 bilinear interpolation을 하여 각 샘플링 포인트의 값을 계산한다.
RoI에서 얻어내고자 하는 정보는 박스 안의 동그라미 점(샘플링 포인트)
이미지 데이터는 정수인 좌표 값만 가지고 있으므로,
화살표로 표현된 방법을 통해 동그라미 점의 값을 구하겠다는 것이다.
화살표가 의미하는 방법은 bilinear interpolation


참고 영상 : https://www.youtube.com/watch?v=kcPAGIgBGRs
'Computer Vision > Object Detection, Segmentation' 카테고리의 다른 글
| [CVPR 2022] Oriented RepPoints for Aerial Object Detection (0) | 2023.03.17 |
|---|---|
| [CVPR 2020] Bridging the Gap Between Anchor-based and Anchor-free Detection via ATSS 리뷰 (0) | 2022.10.25 |
| [MMRotate] Tutorial (0) | 2022.08.26 |
| [MMRotate] 개념 (0) | 2022.08.24 |
| [ECCV 2020] DETR : End-to-End Object Detection with Transformers (Facebook AI) (0) | 2021.12.07 |
