논문 : https://arxiv.org/pdf/1911.11130.pdf
발표 : https://www.youtube.com/watch?v=p3KB3eIQw24&t=27s
키워드 : Deformable 3D Objects
3D reconstruction에는 많은 supervision이 있지만 이것들을 만드는데는 비싼 비용이 든다는 단점이 있다.
따라서 본 논문에서는 다른 additional supervision 없이 오직 single view images만 가지고 학습시키고자 했다. Key idea는 좌우 대칭(bilateral symmetry)을 이용하는 것이다. 이를 위해 Photo-Geometric Autoencoding이란 framework를 만들었다.

0. Abstract
본 논문은 external supervision없이 raw single-view images에서 3D의 변형 가능한 object categories를 학습하는 방법을 제시한다. 이 방법은 input image를 depth(깊이), albedo(반사율), viewpoint(방향), illumination(빛, 조명)으로 고려하는 autoencoder를 기반으로 한다. supervision 없이 하기 위해 많은 object들이 적어도 symmetric structure(대칭 구조)를 갖고 있다는 사실을 이용한다.
<참고> 스테레오 비전(Stereo Vision) : 같은 물체에 대해 서로 다른 장소에서 촬영한 여러 이미지에서 물체의 3차원 정보를 계산하는 학문 분야. 즉 2개의 카메라를 사용하여 3차원 영상을 복원하는 것.
2. Related Work
Structure from Motion (SfM)
SfM과 같은 전통적인 방법은 각 장면의 multiple views와 views 간의 2D keypoint를 매치시킨 것이 input으로 주어진 개별 rigid scenes의 3D 구조를 reconstruct (재구성) 할 수 있다.

예를 들면, 이동하는 카메라로부터 t1시점에 촬영한 영상과 t2시점에 촬영한 영상이 있다면 두 영상간에 동일한 지점을 찾아내고 이 점들을 이용해 Fundamental Matrix 그리고 Epipolar Geometry에 대한 정보를 알아내어 3D로 복원을 하게 되는 것이다.
[출처] [MATLAB 강좌] 컴퓨터비전2편: 스테레오 비전 및 3D 포인트 클라우드|작성자 MathWorks Korea
Shape from X
shading(음영), silhouettes(실루엣), texture(질감), symmetry(대칭) 등과 같은 많은 다른 monocular cues (단안 단서; 깊이 인식을 위해 사용되는 단서 중 한쪽 눈으로 관찰 할 수 있는 단서)가 이미지에서 shape을 복구하기 위한 SfM의 대안 또는 보충제로 사용되고 있다. 특히 본 연구는 shape from symmetry와 shape from shading에서 영감을 얻었다. Shape from symmetry는 대칭 대응이 가능하다면 대칭 이미지를 가상의 두번째 view로 사용하여 단일 이미지에서 대칭 객체를 재구성한다. 또한 descriptors를 사용하여 대칭과 대응을 감지할 수 있다. Shape from shading은 Lambertian 반사율과 같은 shading model을 가정하고 불균일한 조명을 이용하여 표면을 reconstruct 한다.
Category-specific reconstruction
object에 대한 새로운 views를 환각하는 방법으로 Adversarial learning 이 제안되었다. (HoloGAN 등)
우리의 모델이 내부 3D 표현에서 이미지를 생성하기 때문에 하나의 필수적인 요소는 differentiable(미분할 수 있는?) renderer이다. 그러나 기존의 렌더링 pipeline에서는 occlusions(폐색) 및 boundaries(경계) 간의 gradients가 정의되지 않는다. 따라서 몇몇의 soft relaxations가 제안되었다.
3. Method
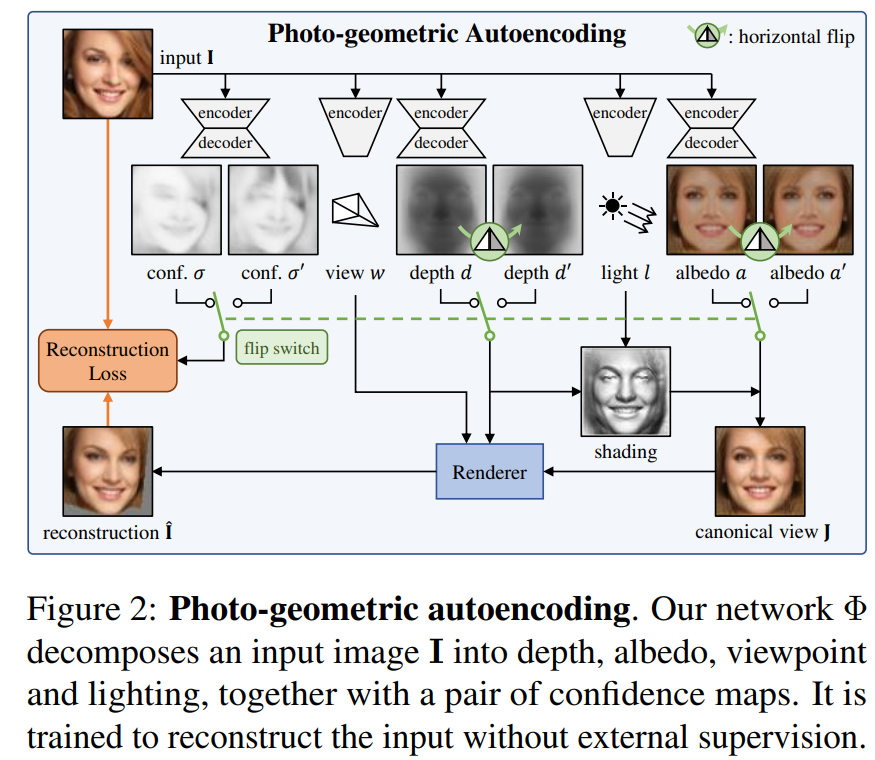
우리의 목표는 object instance의 이미지를 입력으로 받아 출력으로 3D shape, albedo(반사율), illumination(빛, 조명)과 viewpoint로 분해하는 모델 Φ를 학습하는 것이다. (Fig. 2.)
우리는 오직 raw images만 가지고 있기 때문에 학습 목표는 reconstructive이다. 즉, 모델은 네가지 요소의 조합이 input image를 되돌려주도록 훈련된다. 그 결과 factors가 recompose(재구성)되는 방식으로 인해 명시적으로 photo-geometric 의미를 갖는 autoencoding pipeline이 생성된다.
구성 요소에 대한 supervision 없이 이러한 decomposition(분해)를 학습하기 위해 우리는 많은 객체들이 bilaterally symmetric(양측 대칭)이라는 사실을 이용한다. ... (중략 : 완벽하게 대칭이 아닌 것을 해결하기 위핸 방법)
4. Experiments
Datasets : CelebA, 3DFAW and BFM
Metrics : scale-invariant depth error (SIDE), mean angle deviation (MAD)

4.4. Limitations

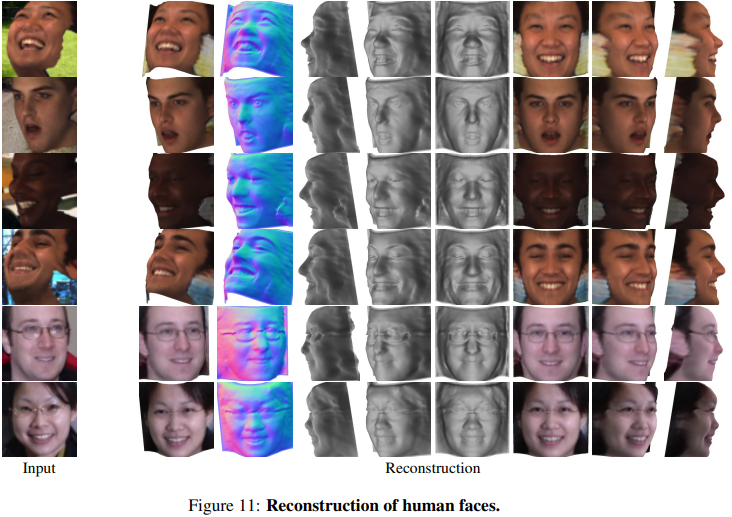
우리의 방법은 extreme facial expression, abstract drawing과 같은 까다로운 시나리오에서 견고하지만 Fig 8과 같은 실패 사례가 있다.
5. Conclusions
본 논문은 object category의 single-view images의 unconstrained collection(제한되지 않은 수집)에서 deformable(변형 가능한) object category 3D 모델을 학습할 수 있는 방법을 제시했다. 이 모델은 개별 객체 인스턴스의 high-fidelity monocular(충실한 단안) 3D 재구성을 얻을 수 있다. 이것은 autoencoder와 유사한 어떤 supervision 없이 reconstruction loss를 기반으로 훈련된다. symmetry(대칭)과 illumination(조명)은 shape에 대한 강력한 단서이며 모델이 의미있는 reconstruction을 하는데 도움을 준다. 우리의 모델은 2D keypoint supervision을 사용하는 현재 SOTA인 3D reconstruction 방법보다 성능이 뛰어나다.