LoRA (Low-Rank Adaptation of LLM)
- HuggingFace에서 개발한 Parameter-Efficient Fine-Tuning (PEFT) 방식 중 하나
- 사전 훈련된 모델 가중치는 고정하고 훈련 가능한 레이어(LoRA adapter 의 A Layer, B Layer) 들을 별도로 붙이고 추가 훈련을 통해 학습
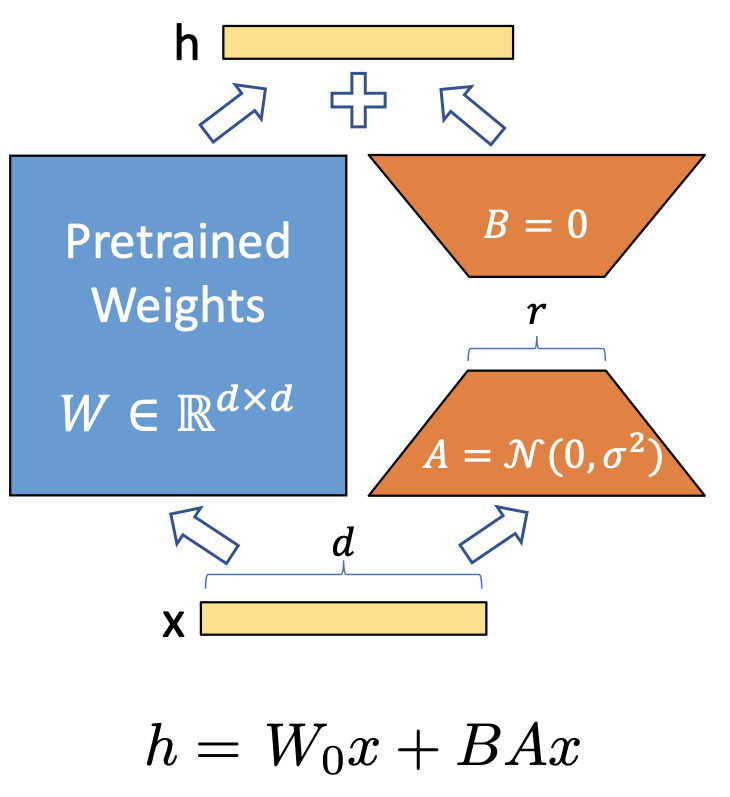
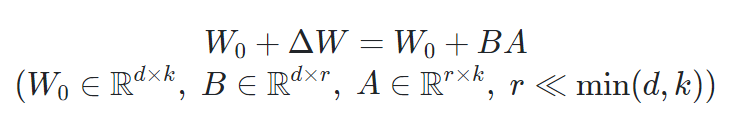
위 식에서 는 frozen, 와 는 trainable한 상태이다. 기존의 LoRA는 트랜스포머 모듈의 query와 value 행렬에 adapt해 붙어있었고, 기존 LLM의 1%도 안되는 trainable 파라미터로 full-finetuning과 거의 동일한 수준의 성능을 보여주었다.
장점
- 작은 크기
- 대기 시간 없이 효율적인 작업 전환
단점
- 모델 자체를 추가 훈련할 때의 성능은 넘을 수 없음
LoRA Hyperparameters
LoraConfig(
r=16
,lora_alpha=8
,target_modules=TARGET_MODULES = ["q_proj", "v_proj"]
,lora_dropout=0.05
,bias="none"
,task_type="CAUSAL_LM"
)
1. r : LoRA : Adapter 파라미터의 차원 갯수 , 기본값은 8 (LoRA adapter의 차원지정)
r 값을 낮게 설정 하면 학습속도가 빨라지고 계산 비용이 적은 훈련 과정을 이끌 수 있지만 생성된 모델의 품질이 낮아질 수 있습니다. 그렇다고 r 을 특정 값 이상으로 설정해도 모델의 품질이 눈에 띄게 향상되지 않을 수 있습니다.
값이 크면 클수록 더 많은 수정이 이루어지며, 모델이 더 복잡해질 수 있음
2. lora_alpha : Adapter 의 Scaling값으로 Adapter 에서 나온 output 값에 곱해지는 값, 기본값은 8
여기서 α는 상수입니다. Adam으로 최적화할 때, 초기화가 적절하게 스케일 조정되었다면 α를 조정하는 것은 거의 학습률을 조정하는 것과 동일합니다.
LoRA가 적용될 때 원래 모델의 가중치에 얼마나 영향을 미칠지 결정. 높은 값은 가중치 조정의 강도를 증가시킴
3. lora_dropout : LoRA 레이어의 드롭아웃 확률, 기본값은 0
훈련 중에 드롭아웃 확률에 따라 무작위로 뉴런을 선택하여 생략하고 과적합을 줄이는 기술입니다.
4. target_modules , 기본값은 None (LoRA Adapter를 적용할 layer 목록)
LoRA로 미세 조정할 때 모델 아키텍처에서 타겟팅할 모듈을 설정합니다.
"r"과 유사하게 많은 모듈을 타겟팅하면 훈련 시간이 증가하고 컴퓨팅 리소스 수요가 증가합니다.
따라서 트랜스포머의 어텐션 블록만 타겟팅하는 것이 일반적입니다.
5. lora_bias : LoRA 바이어스 유형, 기본값은 None
바이어스는 'none', 'all', 또는 'lora_only'가 될 수 있습니다.
'all' 또는 'lora_only'인 경우 해당하는 바이어스는 훈련 중에 업데이트됩니다.
LoRA 사용하기 (ex. gpt2에 적용)
1. 기본 환경 설정
pip install transformers
pip install peft
2. 모델 로드 및 LoRA 적용
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import LoraConfig, get_peft_model
# 모델과 토크나이저 로드
model_name = "gpt2"
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# LoRA 설정
lora_config = LoraConfig(
r=8, # LoRA에서 사용하는 low-rank matrices 어텐션 차원을 정의. 값이 크면 클수록 더 많은 수정이 이루어지며, 모델이 더 복잡해질 수 있음
lora_alpha=32, # 스케일링 계수. LoRA가 적용될 때 원래 모델의 가중치에 얼마나 영향을 미칠지 결정. 높은 값은 가중치 조정의 강도를 증가시킴
lora_dropout=0.1, # 드롭아웃 비율
target_modules=["c_attn", "c_proj"] # LoRA를 적용할 대상 모듈 (GPT-2의 경우)
)
# LoRA 적용
model = get_peft_model(model, lora_config)
# 모델 요약
model.print_trainable_parameters()
AutoModelForCausalLM 이란?
Hugging Face의 transformers 라이브러리에서 제공하는 자동 모델 로더(AutoModel) 중 하나로, Causal Language Modeling (인과 언어 모델링) 작업을 위해 사전 학습된 언어 모델을 불러오는 데 사용됩니다. 이 클래스는 주로 텍스트 생성 작업에 사용되며, 특정 작업에 맞게 모델을 미세 조정하거나 새롭게 훈련할 수 있습니다.
사용 예시
from transformers import AutoModelForCausalLM, AutoTokenizer
# 모델과 토크나이저 로드
model_name = "gpt2"
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 입력 텍스트 설정
input_text = "Once upon a time"
# 입력 텍스트를 토큰화
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
# 텍스트 생성
output = model.generate(input_ids, max_length=50, num_return_sequences=1)
# 출력 텍스트 디코딩
output_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(output_text)
코드 설명
- AutoModelForCausalLM.from_pretrained(model_name):
- 지정된 이름의 사전 학습된 모델을 로드합니다. gpt2를 사용하면 GPT-2 모델을 불러옵니다.
- tokenizer(input_text, return_tensors="pt"):
- 입력 텍스트를 모델이 처리할 수 있는 텐서 형식으로 변환합니다. 여기서 return_tensors="pt"는 PyTorch 텐서 형식으로 반환하라는 의미입니다.
- model.generate():
- 모델을 사용해 입력 텍스트에 이어지는 다음 텍스트를 생성합니다. max_length는 생성할 텍스트의 최대 길이를, num_return_sequences는 생성할 시퀀스의 수를 설정합니다.
- tokenizer.decode():
- 생성된 텍스트를 다시 사람이 읽을 수 있는 문자열 형식으로 변환합니다.
3. LoRA가 적용된 모델 훈련
from transformers import Trainer, TrainingArguments
# 데이터 준비 (샘플 텍스트 데이터)
texts = ["Hello, how are you?", "I am fine, thank you!"]
# 토크나이저를 사용해 데이터 전처리
inputs = tokenizer(texts, return_tensors="pt", padding=True, truncation=True)
# train 설정
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=2,
logging_dir="./logs",
logging_steps=10,
)
# trainer 설정
trainer = Trainer(
model=model,
args=training_args,
train_dataset=inputs["input_ids"],
)
# 모델 훈련
trainer.train()
4. 모델 저장 및 사용
# 모델 저장
model.save_pretrained("./lora_model")
tokenizer.save_pretrained("./lora_model")
# 모델 로드
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("./lora_model")
- LoraConfig: LoRA의 설정을 정의하는 클래스입니다. 여기서 r은 저차원 공간의 랭크를, lora_alpha는 스케일링 계수를, lora_dropout은 드롭아웃 비율을 설정합니다.
- target_modules: LoRA를 적용할 모델의 특정 레이어를 지정합니다. GPT-2 모델의 경우, c_attn과 c_proj 모듈이 주요 타겟입니다.
- get_peft_model: 이 함수는 주어진 모델에 LoRA를 적용하여, 새로운 훈련 가능한 파라미터를 추가합니다.
- Trainer: Hugging Face Trainer 클래스를 사용해 훈련을 진행합니다. 이 과정은 일반적인 모델 훈련과 유사하며, 추가된 LoRA 파라미터만 업데이트됩니다.
QLoRA (Quantized Low-Rank Adaptation)
RoLA와 유사하게 저차원 공간에서의 학습을 기반으로 하지만, 추가로 양자화(quantization) 기술을 활용하여 모델의 파라미터를 4비트(또는 그 이하)로 양자화합니다. 이를 통해 모델의 메모리 사용량을 더욱 줄이고, 훈련 및 추론 속도를 높입니다.
'LLM' 카테고리의 다른 글
| Hugging Face에서 가장 많이 다운로드 된 seq2seq Models: BART, PEGASUS, MT5 (0) | 2024.04.24 |
|---|---|
| Hugging Face에서 가장 많이 다운로드 된 Encoder Models: ALBERT, RoBERTa, DistilBERT, ConvBERT, XLM-RoBERTa, Electra, LongFormer (0) | 2024.04.24 |
| BERT를 활용한 마스킹 단어 예측 (0) | 2024.04.23 |
| Reformer: The Efficient Transformer (ICLR 2020) (0) | 2024.04.23 |
