코드 : github.com/SystemErrorWang/White-box-Cartoonization

이미지를 만화처럼 바꿔주는 Cartoonization model이다.
현재 진행하고 있는 연구 분야라 논문을 읽어 보았는데, Cartoon만의 특징적인 representation 들을 캐치해서 White-box model로 만든 게 인상적이었다. 일반적인 Style Transfer model이 아닌 이렇게 특정 도메인에 특화된 style transfer model도 굉장히 흥미롭다. test code도 돌려봤는데 어떤 이미지를 사용하든 만화처럼 잘 변환하는 것을 확인할 수 있었다.
1. Introduction

본 논문은 만화의 특징을 잘 나타내는 세 가지 특징을 이미지에서 별도로 추출해서 학습시키는 White-box model이다.
Surface / Structure / Texture representation 을 추출하는데 이 세가지 표현들이 어떤 것인지 자세하게 살펴보자.
1.1 surface representation

만화는 실제 사진보다 평평하고 매끄러운 표면을 가지고 있다. 따라서 이미지에서 부드러운 표면을 나타내는 가중 저주파 성분을 추출한다.

이미지도 주파수로 표현할 수가 있는데 위의 그래프와 같다. 중심을 이루는 곡선이 저주파를 의미하는 것으로 일반적인 배경을 나타낸다. 세부적인 디테일들을 제거한 이미지인데 이런 저주파 성분을 추출함으로써 만화의 부드러운 표면을 표현하고자 한 것이다. 자잘한 곡선은 고주파를 의미하는 것으로 밝기의 변화가 많은 경계선 영역을 나타낸다. 나는 개인적으로 이해를 돕기 위해 고주파=고화질, 저주파=저화질 이미지라고 생각했다.
1.2 structure representation

다음으로 전반적인 구조를 나타내는 Structure representation이다. 만화는 실제 사진보다 희소한 컬러 블록으로 이루어져 있다. 예를 들어, 실제 사람의 머리카락은 굉장히 다양한 색상을 가지고 있지만 만화에서는 갈색, 검정색 등 그냥 하나의 색상으로 표현한다. 이를 표현하기 위한 방법을 한 줄로 말하자면 "segmentation 기법을 이용해 희소한 컬러 블록으로 구조를 표현한 것" 이라고 할 수 있을 것 같다. 만화적인 특징을 뽑아내기 위한 방법들이 꽤나 그럴듯하다고 느껴진다.
1.3 texture representation

실제 사진과 만화의 대표적인 차이점이라고 할 수 있는게 바로 펜선이다. 실제 사진에는 펜선이란게 없지만 만화에는 펜선이라는 게 존재한다. 이러한 특징들을 뽑아내기 위해 입력 이미지를 single-channel intensity map으로 변환해 색과 휘도를 제거하고 상대 픽셀 강도를 보존했다.
2. Related Work
2.1 Felzenszwalb algorithm
Structure Representation을 추출하기 위해 Felzenszwalb algorithm을 사용한다.
"본 작품에서는 Felzenszwalb 알고리즘[11]을 따라 학습 가능한 구조표현을 달성하기 위한 만화 중심의 segmentation 방법을 개발한다. 이러한 표현은 심층 모델이 글로벌 콘텐츠 정보를 포착하고 셀룰로이드 스타일의 만화 워크플로우를 위해 실제로 사용 가능한 결과를 도출하는 데 중요하다." 라고 설명하고 있는데 셀룰로이드 스타일의 만화 워크플로우 라는 부분이 무엇인지 검색해도 잘 나오지가 않고 무엇인지 잘 모르겠다. 좀 더 자세한 설명이 나와 있었다면 좋았을 것 같다..



2.2 deep guided filtering network (DGF)
Surface representation을 추출하기 위해 deep guided filtering network (DGF)를 사용한다.
DGF는 GIF를 end-to-end로 학습할 수 있게끔 발전시킨 것이다.
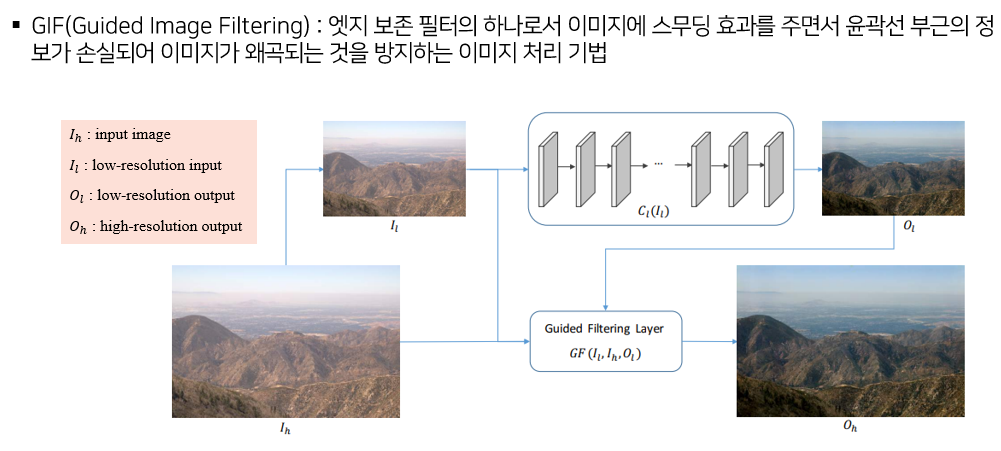

이 필터를 거치게 되면 고양이 예시에서 알 수 있듯이 윤곽선은 선명하게 보존하면서 안의 내용을 부드럽게 바꿔줄 수 있다.
3. Proposed Approach

전체적인 프레임워크는 위와 같다. 이미지는 표면 표현, 구조 표현, 텍스처 표현으로 분해되며, 3개의 독립 모듈이 도입되어 해당 표현을 추출한다.
generator G와 두 개의 discriminators Ds와 Dt가 있는 GAN 프레임워크가 제안되는데, 여기서 Ds는 모델 출력물에서 추출한 표면 표현과 만화를 구별하는 것을 목표로 하고 Dt는 출력물과 만화에서 추출한 texture representation을 구별하는 데 사용된다.
사전 훈련된 VGG 네트워크[35]는 high-level features을 추출하고 추출된 구조 표현과 출력 간, 입력 사진과 출력 간에도 글로벌 콘텐츠에 공간적 제약을 가하는 데 사용된다. 각 구성 요소의 Weight는 손실 함수에서 조절할 수 있어 사용자가 출력 스타일을 제어하고 모델을 다양한 사용 사례에 맞게 조정할 수 있다.
3.1 Surface Representation

이미지를 매끄럽게 하고 동시에 글로벌 의미 구조를 유지하는 edge preserving filtering을 위해 a differentiable guided filter를 채택한다. $F_{dgf}$로 표시되며, 이미지 $I$를 입력으로, 그리고 그 자체를 가이드 맵으로 삼으며
추출된 표면 표현 $F_{dgf}(I,I)$을 텍스처와 디테일이 제거된 상태로 반환한다. Model outputs과 reference cartoon images의 표면이 유사한지 판단하기 위해 판별자 Ds를 도입하고, 추출된 표면 표현에 저장된 정보를 학습할 수 있도록 generator G를 안내한다. $I_p$는 입력 사진을 나타내고 $I_c$는 참조 만화 이미지를 나타내도록 하며, 위와 같이 surface loss를 공식화한다.
3.2 Structure Representation


3.3 Textural Representation

3.4 Full model

4. Experimental Results






Figure 8은 각 표현에 대한 가중치를 바꿔가며 실험한 결과이다. 이처럼 작가가 원하는대로 조정할 수 있다는 게 본 논문의 큰 특징이다.
(b) Texture weight를 늘리면 이미지에 디테일이 더해져 초원과 돌 등에 풍부한 디테일이 보존된다. 데이터셋 분포를 조절하고 텍스처 표현에 저장된 고주파 디테일을 강화하기 때문이다.
(c) Structure weight를 늘리면 질감이 부드러워지고 디테일이 적어지기 때문에 구름과 산이 보다 매끄러워진다. guided filtering이 훈련 샘플을 매끄럽게 하고 질감이 촘촘한 패턴을 줄이기 때문이다.
(d) Surface weight를 늘리면 보다 추상적이고 희박한 이미지를 얻을 수 있다. 산의 디테일이 희박한 색체 블록으로 추상화됨을 볼 수 있다. seletive search algorithm이 훈련 데이터를 평탄하게 만들어 구조 표현으로 추상화하기 때문이다.
결론적으로 블랙박스 모델과 달리 이러한 화이트 박스 방식은 관리가 가능하고 쉽게 조정가능 하다.

5. Conclusion
- 실제 사진에서 고품질의 만화화 이미지를 생성할 수 있는 화이트 박스 프레임워크를 제안했다.
- 이미지는 Surface / Structure / texture representation 으로 분해된다.
- Loss function 에서 각 표현의 가중치를 조정해 출력 스타일을 제어할 수 있다.
